

We kunnen het niet voldoende herhalen : internet vormt vandaag een goudmijn aan informatie en getuigenissen. De huidige crisis vormt hierop geen uitzondering. Maar hoe pakken we de bewaring van deze informatie aan ? Welke Touls kunnen ons helpen voor de offline bewaring en raadpleging?
In een eerste artikel (hier), geeft onze collega Willem Vannest van de Universiteit Antwerpen een eerste reeks raadgevingen en reflectiepistes om jouw webarchiveringsproject te lanceren.
In deze bijdrage stellen we enkele archiveringsoplossingen voor uit de Handleiding digitaal archiveren voor particulieren en tools en programma’s van de International Internet Preservation Consortium.
We proberen het kort te houden : aarzel vooral niet om zelf aan de slag te gaan met de verschillende applicaties.
Belangrijke opmerkingen
We pretenderen hier niet dat we doorwinterde informatici zijn en we zullen dan ook niet al te diep ingaan op de details in deze bijdrage.
Daarnaast is het ook belangrijk om tijdens het downloaden en archiveren van afbeeldingen, videos en teksten op websites rekening te houden met het auteursrecht. Vrij beschikbaar betekent niet automatisch vrij van rechten. De bewaring op lange termijn om (cultuur)historische redenen is op zich niet problematisch voor een publiek beschikbare website. Het hergebruik en de communicatie ervan naar derden kan meer discussie opleveren. Het valt daarom aan te raden om aan de beheerder van een website, blog of pagina op een sociaal netwerk de expliciete toestemming te vragen om een deel van een website te archiveren en te bewaren op de lange termijn.
Wees heel duidelijk over uw doelstellingen : het gaat hier om de bewaring van een getuigenis voor toekomstige generaties en niet om een onderhandse manier om bv. foto’s te hergebruiken.
Daarnaast dient ook rekening te worden gehouden met aspecten zoals gegevensbescherming en privacy: de aanwezigheid van commentaren kan er bijvoorbeeld voor zorgen dat je gearchiveerde content niet zomaar kan worden gepubliceerd op internet, maar dat deze wel nog beschikbaar blijft voor historisch en wetenschappelijk onderzoek.
Voorstelling van de tools
- Capture door derden
Vooreerst is het belangrijk om te weten of u over de nodige technische middelen beschikt (server, infrastructuur, enz.) beschikt om een website te bewaren en of u de moed heeft om eraan te beginnen…
Aarzel dus niet om de Wayback Machine van het Internet Archive te gebruiken : “Save Page Now” maakt het mogelijk om webpagina’s eenvoudig te archiveren. Deze website is de oudste en bekendste op vlak van webarchivering en biedt al jarenlang snapshots aan van websites die inmiddels van het web verdwenen zijn. - Een post op een sociaal netwerk
Maak de zaken niet ingewikkelder dan nodig: de eenvoudigste oplossingen zijn soms de beste. Wanneer we naar sociale media kijken wilt u misschien één post bewaren als getuigenis. Misschien volstaat het om hiervan een printscreen te nemen. Het is niet altijd noodzakelijk of pertinent om het grote geschut boven te halen. - U wenst één pagina of een klein aantal pagina’s te bewaren ?
a. Oplossing zonder account : twee extensies voor Firefox en Chrome
Het merendeel van de tijd zult u zich uit de slag kunnen trekken met een simpele browserextensie. "SingleFile” of "Save Page WEzijn twee tools die het mogelijk maken om pagina’s op te slaan in HTML-formaat en ze te bewaren als één bestand. De extensies bestaan zowel voor Google Chrome/Chromium als voor Firefox.
Deze extensies werken ook om op sociale media gedeeltes van pagina’s op te slaan: u scrolt tot de datum die u als startpunt wil nemen (in dit geval, het begin van de lockdown) en gebruikt dan de extensie. Voor lange posts dient u deze ook te openen (meer/verder lezen).
b. Oplossing met acount: www.webrecorder.io
Met een eenvoudig, gratis aan te maken account kunt u collecties creëren met een geheel van pagina’s. De pagina’s van eenzelfde collectie kunnen gedownload worden in WARC-formaat. Er zijn aparte functionaliteiten voorzien (autopilot) voor het registreren van conten op sociale netwerken, YouTube, soundcloud, enz.
c. Een oplossing voor Linux: ArchiveBox
Met ArchiveBox kunt u eveneens een reeks pagina’s bewaren op basis van een map met bladwijzers of een browsergeschiedenis.
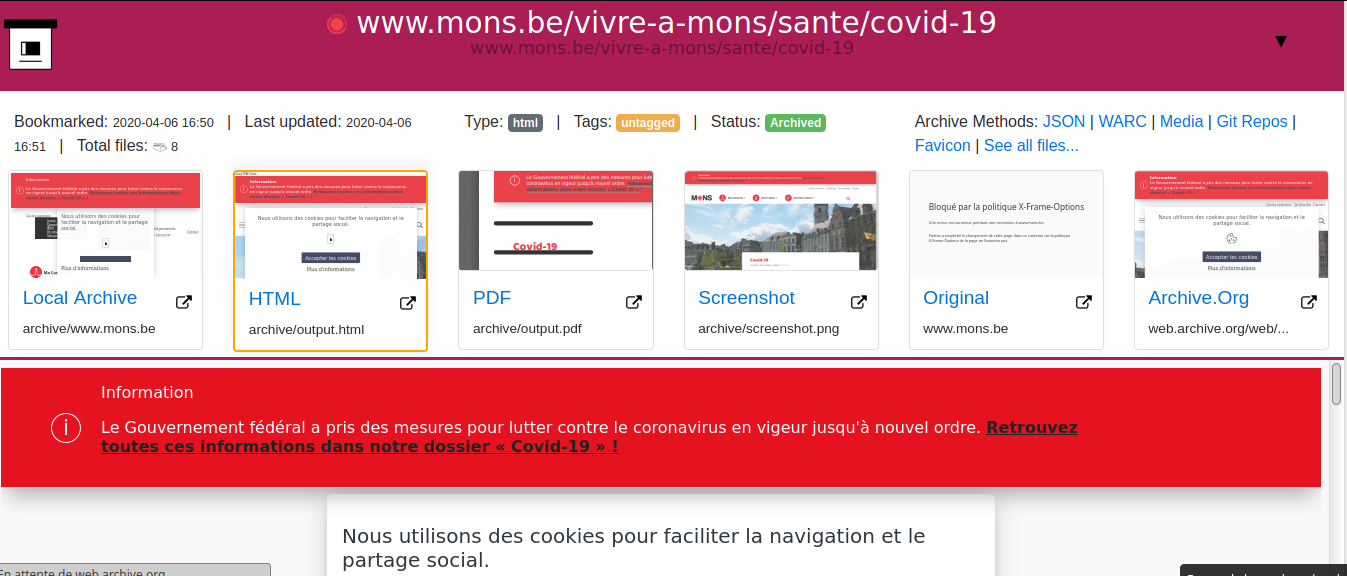
De eenvoudige html-interface geeft toegang tot verschillende formaten, met een link naar de originele website, de datum van archivering en eventuele updates. Deze metadata maken het makkelijk om een interface aan te bieden aan een eindgebruiker of een lezer.
Een interessant element van deze software is dat er vrij eenvoudig een offline portaal mee kan gecreëerd worden waarin gearchiveerde versies in alle formaten kunnen worden aangeboden: HTML, PDF, PNG, WARC…
4. Een volledige website of een groot gedeelte ervan
a. De meest courante oplossing: Httrack
De bekendste oplossing om volledige websites te capteren is Httrack, een gratis opensource programma dat zowel onder Linux als onder Windows werkt (en dit zonder verdere installatie).
De software biedt de mogelijkheid om heel eenvoudig volledige websites op te slaan in HTML formaat voor een offline raadpleging, en dit op basis van een url voor een volledige website (bv. www.gemeenteX.be.) of voor een deel ervan (bv. www.gemeenteX.be/gezondheid/covid19).
De software biedt de mogelijkheid om de diepte van archivering te parametreren (te bewaren aantal submenu’s, links naar externe websites, enz.). Er wordt ook deels rekening gehouden met dynamische aspecten van websites (video, flash, enz.).
Uiteraard is het ook mogelijk om een individuele pagina op te slaan.
b. Een mogelijkheid voor Linux: Wget Wget
Voor archivarissen die wat verder willen gaan is er ook Wget voor Linux (er bestaat een Windows-port, maar deze is niet ingebouwd in het systeem en moet apart gedownload worden). Wget werkt via de command-line interface en biedt de mogelijkheid om WARC-output te genereren. Aarzel niet om de documentatie op de Ubuntu wiki te raadplegen. U vindt er een eerste overzicht van de functionaliteiten op https://www.gnu.org/software/wget/manual/
Gearchiveerde bestanden raadplegen
Wat nu gedaan met de gearchiveerde bestanden ? Hoe kunnen ze geopend worden? Hoe kunnen ze hergebruikt worden?

- Een enkele HTML-pagina: SingleFile, Save Page We
Het raadplegen van een enkele HTML-pagina is vrij eenvoudig: de courante webbrowsers hebben hier geen enkel probleem mee. - HMTL-bestand(en) met gelinkte elementen/mappen: Httrack
De raadpleging verloopt eveneens via een webbrowser.
Waarom zou men kiezen voor dit formaat? Alle verschillende elementen van een pagina worden opgeslaan. Zo kunnen alle afbeeldingen van een website of een pagina geselecteerd worden.
Let wel op: indien de bestanden verplaats worden naar een andere plaats of drager moet u ervoor zorgen dat alles samen wordt gekopieerd. - WARC-bestand (Web Archives) : Wget, webrecorder.io
Om dit bestandstype te lezen is aparte software nodig. Die is online beschikbaar (https://wab.ac/) of hij kan lokaal gedownload worden. Je kan bv. Webrecorder player downloaden op je eigen computer. - Hybride oplossing: ArchiveBox
Globaal genomen werkt de raadplegingsinterface van ArhiveBox zoals een klassieke webbrowser. De interface geeft toegang tot meerdere versies, twee in HTML, één in PDF en een printscreens alsook een link naar de originele website en een verwijzing naar de Wayback Machine van Internet Archive. Dit biedt de gebruiker meerdere opties: een printscreen behoudt sowieso de grafische layout van een pagina, daar waar een HMTL-bestand dit niet altijd doet. Eén van de menu’s biedt eveneens de mogelijkheid om bestanden in WARC of Json formaat te downloaden.